#017 CRO: técnicas para pequeñas muestras
En esta edición haremos un repaso a diferentes aproximaciones que giran en torno a la gran pregunta: ¿qué hacer en escenarios con bajas muestras?

¿Puedo practicar experimentación con bajas muestras?
He aquí la gran pregunta. Si llevas un tiempo dedicado a esto más tarde o más temprano te harán esta pregunta y la respuesta no es nada simple. De entrada es un ¡no! pero conforme avanzas y aprendes un poco de este oficio te das cuentas de que hay aproximaciones técnicas que pueden permitirnos desentrañar la respuesta a esta repetida pregunta.
Ahora sí, empieza CRO: técnicas para bajas muestras.

Disclaimer
En primer lugar, en este post me pondré especialmente técnico, aún así, pienso que va a ser de fácil seguimiento (o eso pretendo) porque no tenemos tú y yo ningún tipo de prisa cuando se trata de experimentación y bajas muestras, ¿verdad?
En segundo lugar, no esperes soluciones mágicas. La ausencia de una muestra suficiente para experimentar es un problema por cuestiones elementales que se detallarán a continuación.
Sé lo que estás pensando: “¿por qué hacer un post sobre bajas muestras si tener una muestra pequeña es un impedimento para experimentar?” Debo decirte, querido lector, que lo importante no es el tamaño de la muestra, sino lo que haces con ella. Pensar que lo único que importa es la n es falaz.
Ahora sí, empezamos.
¿Qué es una muestra pequeña?
Esta es la primera pregunta que deberíamos hacernos. ¿No dependerá del contexto empresarial? ¿no dependerá de lo que queramos medir? ¿no dependerá de la población? ¿cómo saber de entrada si tenemos una capacidad de obtención de muestra suficiente en nuestro activo digital?
En el contexto de la experimentación online controlada, la obtención de la muestra no sucede como vemos en la siguiente imagen. En la carrera habitualmente aprendes que la muestra se obtiene de un conjunto poblacional previo pero no podemos olvidar que cuando ejecutamos un test AB no es necesariamente así.
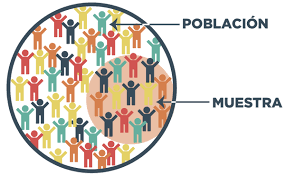
En la mayoría de negocios online, cuando planeamos un experimento online controlado, estamos tratando de hacer una inferencia sobre los futuros usuarios (recurrentes o nuevos, en función del tipo de segmentación) desde que se activa el experimento.
Eso implica que, aunque puede haber una cierta cadencia y frecuencia común en el comportamiento de los usuarios antes y después del experimento, bien sabrás que la naturaleza del tráfico puede variar en función de múltiples causas: cambios en estrategias de puja, updates de Google, promociones agresivas en canales de adquisición específicos, problemas de rendimiento web que afectan a la velocidad, entre otros.
“Hic sunt dracones” se mostraba en los viejos mapas e indicaba ese territorio inexplorado y desconocido y es que, no nos engañemos, nadie (ya seas una empresa grande, pequeña o gigantesca) puede saber si mañana no habrá una caída/subida en tu sitio web de un canal concreto que provocará un tipo de tráfico y comportamiento en métricas cuya naturaleza es nueva.
La muestra necesaria en un experimento dependerá entonces de otra clase de cuestiones más allá de lo que uno pudo aprender en “estadística 1 y 2”. No profundizaré en esta cuestión ahora, pero no hace mucho la buena gente de Spotify publicó un estudio sobre la cuestión del tiempo como valor fundamental en la validez de los experimentos, más allá de la muestra.
¿Qué es entonces una muestra pequeña? Será aquél insuficiente para tomar una decisión en base al cálculo realizar para estimar el tamaño de la muestra. No obstante, el cálculo de la muestra no se hace como pudiste aprender en la carrera: no se tiene en cuenta la población previa para un test AB clásico, sino otra serie de cuestiones.
¿Cómo se calcula el tamaño de la muestra?
En mi libro “Experimentación Online: metodología, estrategia, datos y casos reales” que sale a la venta el 27 de marzo de 2025, dedico una muy buena parte a la compleja e interconectada cuestión del cálculo de la muestra para explicar una serie de cuestiones (deberás leerlo para enterarte 😉).
Sin tampoco entrar en harina, te diré que el cálculo de la muestra en un test AB depende de cuestiones como el tipo de hipótesis (una o dos colas), el nivel de significancia, la potencia o la asunción de la varianza de cada grupo una vez lanzado el test, entre otras cuestiones. De hecho, hay varias maneras de calcular la muestra como apuntó en su día Evan Miller en LinkedIn.
La fórmula más esencial del cálculo de la muestra es la siguiente y quiero que la retengas, porque nos irá de perlas que la tengas presente a lo largo de las técnicas que voy a presentar a continuación:
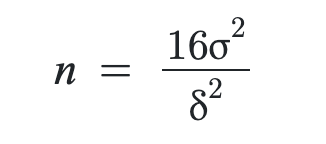
Ahora sí, empezamos con una serie de aproximaciones para escenarios con bajas muestras, iremos de más típicas y básicas a más avanzadas y técnicas.
Aproximaciones para bajas muestras
1. Modificar MDE
Como muchos de aquí sabrán, la muestra de un test AB se determina a partir del MDE lo cual abre la puerta a una cuestión que ya se explicó en la edición 10 de Leanalytics.
Si necesitamos identificar como significativo un impacto menor, neccesitaremos más muestra.
Si necesitamos identificar como significativo un impacto mayor, neccesitaremos menos muestra.
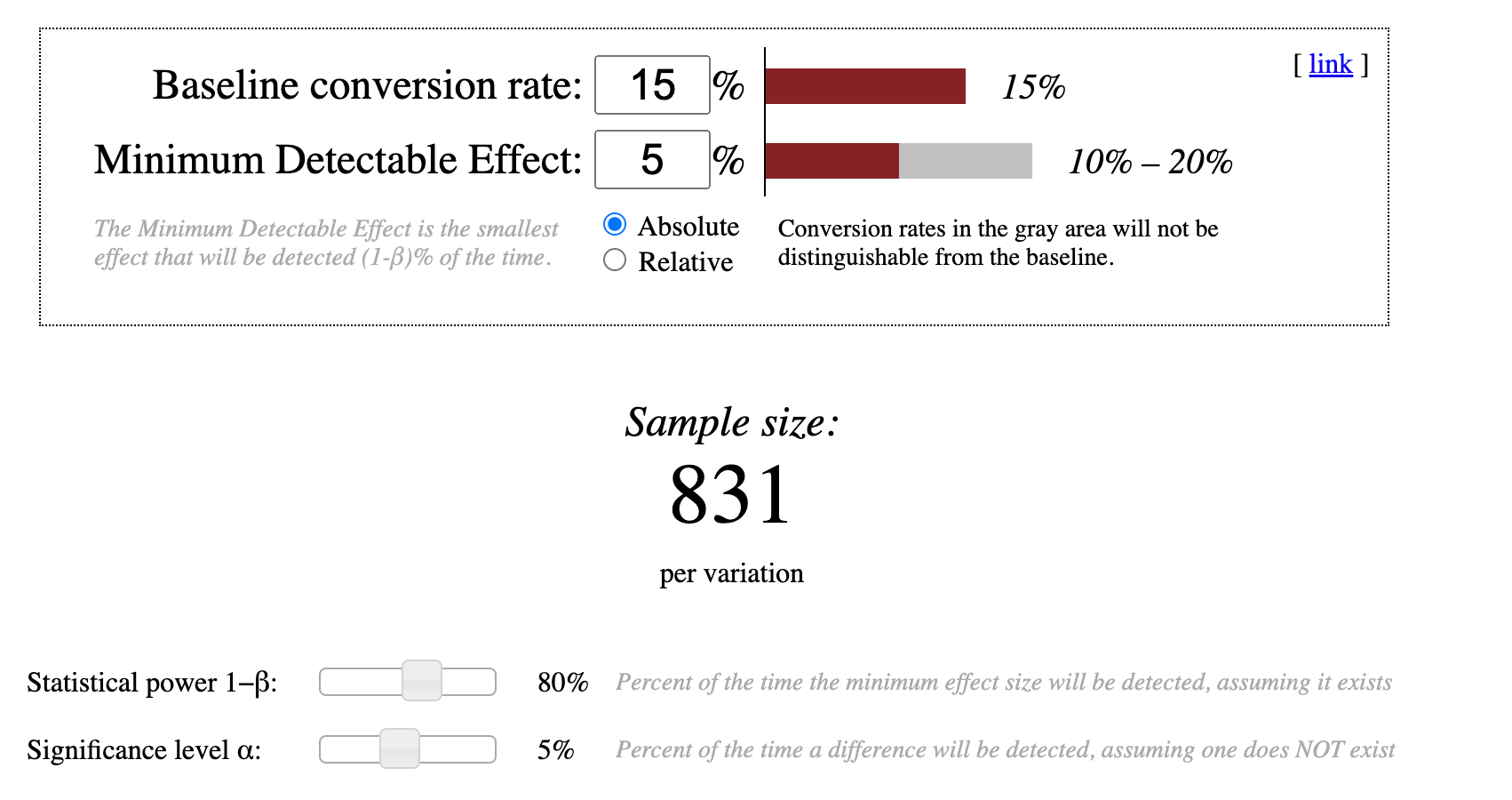
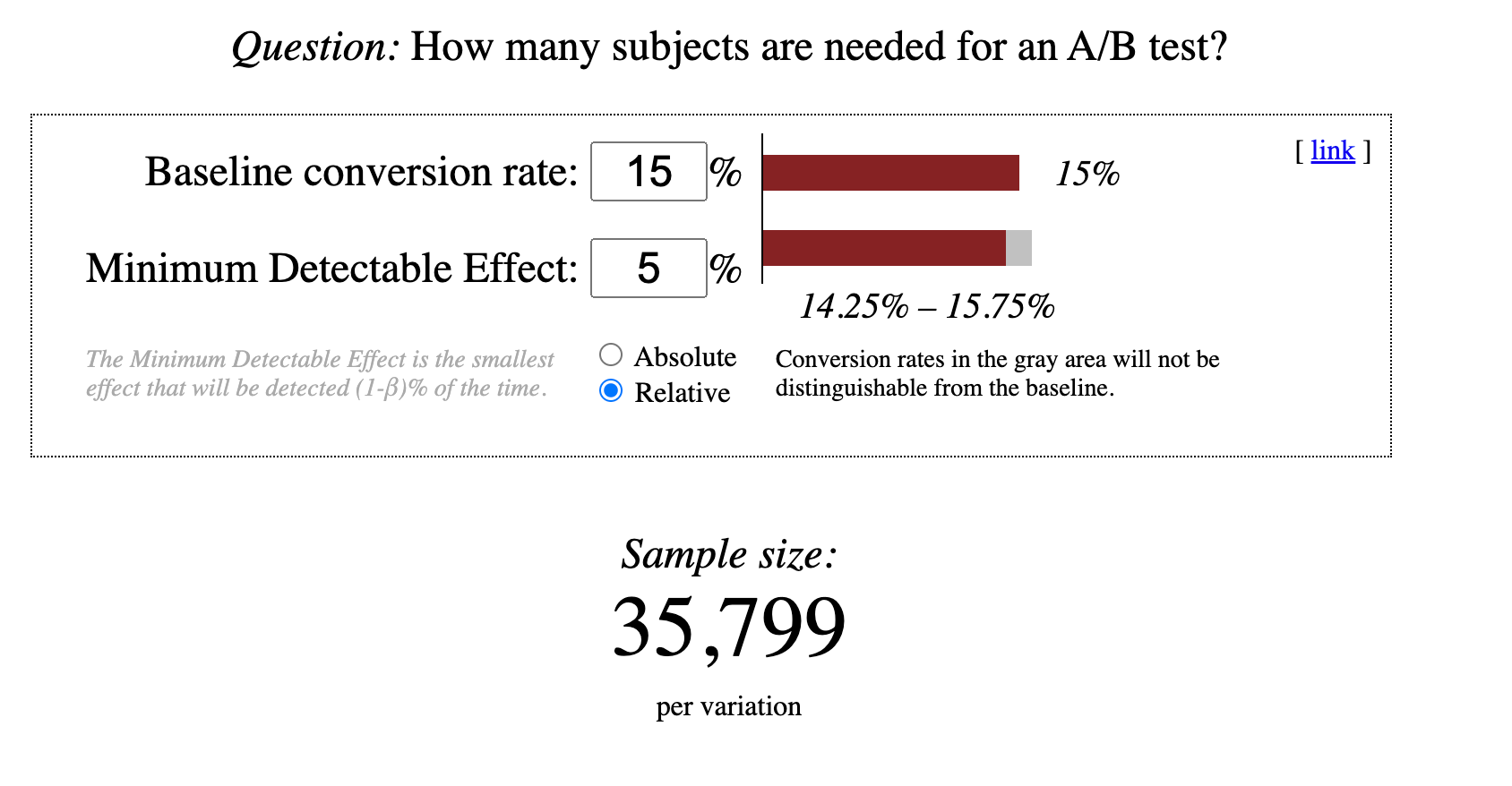
La calculadora de Evan Miller bien lo muestra. En la siguiente figura vemos que para detectar un impacto de 5 puntos porcentuales (de 10 a 20) solamente necesitaríamos 831 usuarios por grupo. La duración del experimento dependerá de cuánto tiempo tardas en tener todo ese tráfico.
Sin embargo, si el MDE es inferior, como en la siguiente figura, veremos que es necesaria mucha más muestra, lo que aumentaría el número de semanas en las que un experimento debería estar activo. Esto no tiene necesariamente nada que ver con el hecho de calcular el MDE de manera relativa o absoluta, es por el tamaño del efecto que quieres detectar (14,25% - 15,75%).
Pros y contras de utilizar el MDE
Este método nos mostraría que entonces “la muestra necesaria” no es una cuestión del tráfico que tenemos, sino del impacto que queremos o podemos medir de manera fiable. Sin embargo, este método tiene una serie de pros y contras.
Pros:
Es sencillo de aplicar ✅
Es modulable ✅
Es (más) fácil de explicar a stakeholders no orientados a la experimentación online que otros métodos ✅
Contras:
Está sujeto a la famosa frase de Ronald H Coase: “if you torture the data long enough, it will confess to anything” ❌
Está duramente condicionado, también, al efecto que estás generando mientras el experimento está en producción, lo cual obliga a una estimación de la muestra dinámica e iterativa 💡
Generar un impacto del 50% en los primeros días puede llegar a ser sencillo y no ser suficientemente fiable aunque tengas la muestra necesaria y un impacto estadísticamente significativo. No tiene en cuenta aspectos como los efectos de novedad o la regresión a la media que puede haber en tests AB. ❌
La configuración del MDE es una cuestión controvertida a la que dedico varias páginas en el libro “Experimentación Online” a cómo realmente llevar a cabo esta cuestión pero, ya te adelanto: ninguno de los métodos que se mostrarán en esta edición tiene solo pros y cero contras, lo cual señala la naturaleza de este trabajo.
2. Selección de métricas
Imagina un comercio electrónico en el que deseamos hacer un experimento en la página de producto ya que hemos detectado un punto de mejora a la hora de añadir a carrito: todo un clásico, ¿verdad?
Vale: ¿qué métrica utilizas? A priori hay dos grandes escuelas: si hacces la certificación de Optimizely te recomendarán que utilices como métrica primaria add_to_cart y nada más mientras que en otros foros se recomendará que trabajes con una baraja de métricas como add_to_cart, begin_checkout y purchase, tanto como primarias como guardrail metrics.
No olvides: no existe un procedimiento estándar porque no existe academia en todo esto. La experimentación online es un oficio en el que hay una importante capa de ciencia pero, incluso en estadística o el tratamiento avanzado de datos al final todo consiste en el enfoque que tú le das al problema.
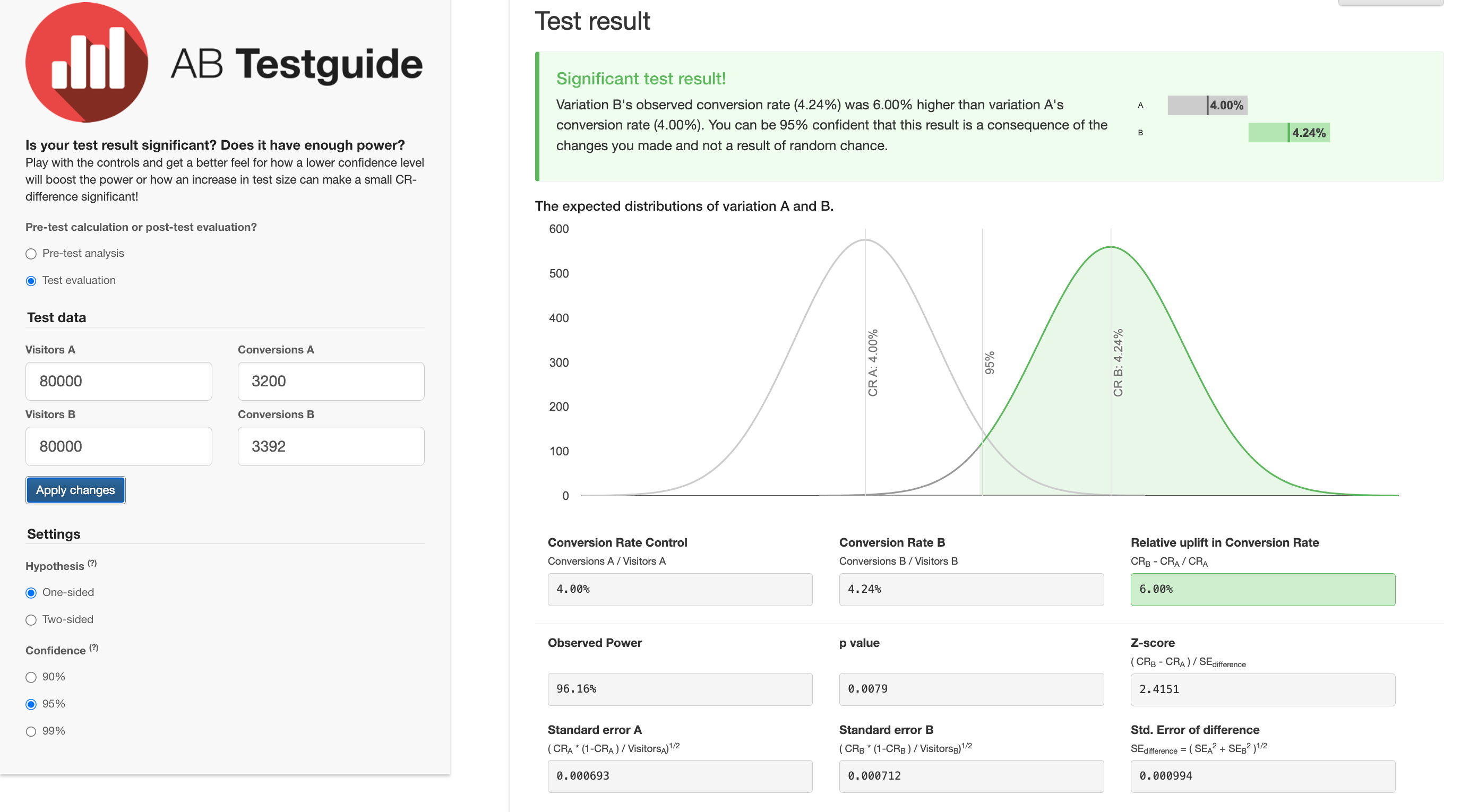
Veamos en acción cómo la elección de la métrica puede modificar tu diagnóstico de un experimento online. En la siguiente figura vemos el escecnario en el que solo tenemos en cuenta como métrica primaria (la que principalmente determinará qué variante gana) add_to_cart. La diferencia relativa entre ambos grupos es del 6% y tenemos una p-valor de 0.0079.
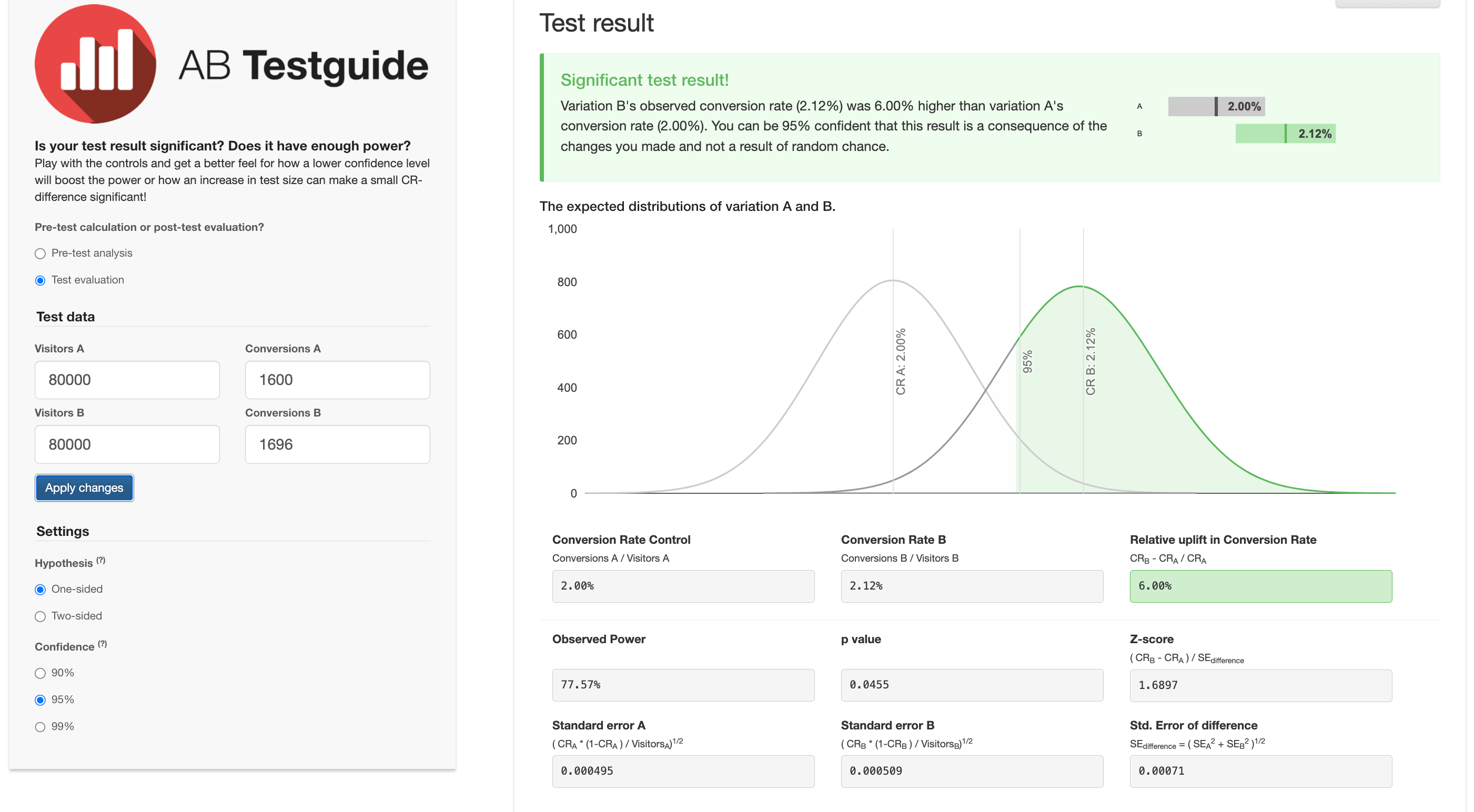
Sin embargo, en la siguiente figura, cuyo escenario es el de que solo tenemos en cuenta métricas más lejanas al lugar en el que sucede el experimento (en este caso purchase) vemos lo siguiente:
Mismo crecimiento en purchase: +6%
Misma muestra: 80.000 por grupo
¿Qué cambia?
Número de conversiones (1600-1696) y por ende el conversion rate de ambos grupos y la diferencia absoluta (2,00 a 2,12), aunque no la relativa (6%)
Un intervalo de confianza más amplio en la figura 17.7 que en la 17.6
Z-Score menor en 17.7 (1.6897) que en 17.6 (2.4151).
Además, la p-valor es de 0.0455. Es decir, aunque es estadísticamente significativa, está más cerca de nivel de significancia (0.05). ¿Qué significa todo esto?
Aquí debemos hacer una pequeña pausa y entender una serie de conceptos. El afán por contar con una muestra suficiente tiene un único objetivo en el contexto de los experimentos online: poder tomar una decisión lo más fiable posible. Si no contamos con la muestra suficiente, a priori, la decisión que tomemos es menos fiable (que no significa errónea). Es una cuestión de probabilidad y de gestión de riesgo.
Sin embargo, aquí tenemos la misma muestra, pero lo que ha cambiado primariamente ha sido el número de conversiones y los parámetros asociados. Así, el efecto que generemos también va a condicionar duramente la muestra necesaria ya que en el escenario de la figura 17.7 tenemos una p-valor de 0.0455 que, si bien es estadísticamente significativa, podría tratarse de un falso positivo.
Habitualmente, los tests cuya p-valor está cerca de 0.05 son más proclives a caer en falsos positivos o incluso en falsos negativos, arrojando la idea de gradualidad en la p-valor resultante de un experimento. Así, técnicas como meta-análisis con técnicas como Stoufer o Fischer permiten averiguar si realmente nuestros experimentos son realmente fiables.
Así, la selección de la métrica a la hora de analizar un experimento online también condiciona el tamaño de la muestra necesaria y, sobre todo, la fiabilidad de nuestro diagnóstico. Esto es especialmente relevante cuando trabajamos con métricas más alejadas del punto de cambio (purchase), donde la varianza y variabilidad inherente puede requerir muestras más grandes para alcanzar el mismo nivel de fiabilidad.
Pros y contras de seleccionar métricas cercanas al punto de cambio como primarias
Pros:
Es sencillo de aplicar ✅
Aumenta la fiabilidad 💡
Como podemos esperar MDE más altos, podríamos contar con menor muestra para obtener la misma fiabilidad. ✅
Contras:
¿Qué hacemos con las transacciones y los ingresos? ¿los tenemos únicamente en cuenta como guardrail metrics? es demasiado naíf ❌
Puedes cometer el error de aplicar mejoras locales que no afectan (o incluso empeoran) a nivel global, lo que afectará tus proyectos de experimentación online a medio plazo. ❌
3. Permutation Tests
Ahora sí, vamos a empezar con la parte más técnica de esta edición. Descubrí los tests de permutación cuando leí este libro sobre estadística aplicada a ciencia de datos a principios de 2021 y desde entonces siempre lo he tenido en la recámara como aproximación antes escenarios con bajas muestras.
Un test de permutación “es un test de significancia estadística para el estudio de diferencias entre grupos. Fue desarrollado por Ronald Fisher y E.J.G. Pitman en 1930. La distribución del estadístico estudiado (media, mediana…) se obtiene calculando el valor de dicho estadístico para todas las posibles reorganizaciones de las observaciones en los distintos grupos. Dado que implica calcular todas las posibles situaciones” (Fuente: https://cienciadedatos.net/documentos/23_resampling_test_permutacion_simulacion_de_monte_carlo_bootstrapping)
Veamos esto con un ejemplo. Imagínate que apenas cuentas con un puñado de usuarios (15 usuarios por grupo) y a cada usuario se le adjudica un ticket medio determinado. Lo que hacemos cuando aplicamos un t-test, por ejemplo, es determinar si la diferencia en la media entre ambos grupos es estadísticamente significactiva.
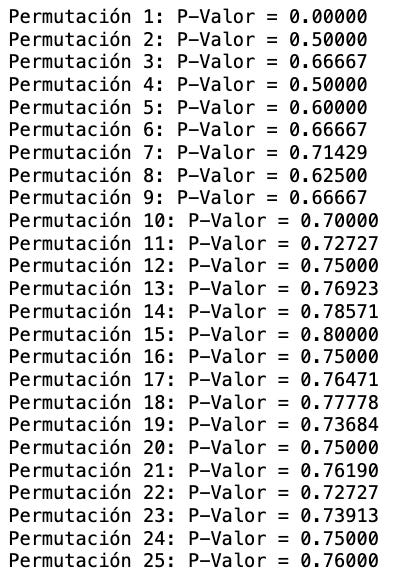
La aproximación en un test de permutación es lo que vemos en la siguiente figura (el gif de las alpacas): un test de permutataciín realiza n remuestreos (resasmpling) y recalcula el mismo número de veces la diferencia entre ambos y la p-valor resultante.

¿Cómo funciona esto exactamente? Cada nueva permutación (es decir, combinación posible en un intercambio de usuarios de grupo de control a variante y viceversa) te entrega una nueva p-valor y un nuevo resultado del experimento sin añadir nueva muestra. Así, con cada nueva permutación podemos afinar la p-valor rseultante como se ve en la figura 17.9 que, al final, resulta lineal cercana a 0.80 de p-valor (resultado estadísticamente no significativo).
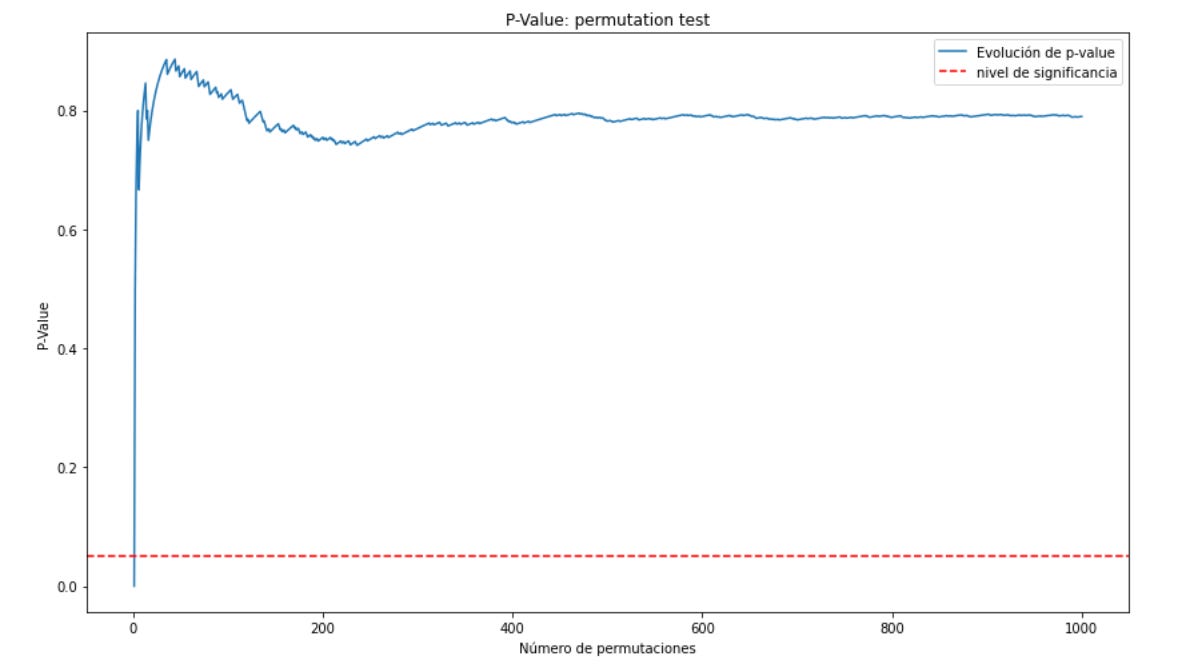
Fíjate que en la primera permutación la p-valor fue muy, muy reducida y conforme se realizan permutaciones cada vez es más lineal. Esto es útil para aumentar la fiabilidad de los diagnósticos de un experimento online incluso con bajas muestras. Si lo prefieres ver con números cómo evoluciona la p-valor conforme se realizan permutaciones, lo puedes ver en la figura 17.10.
Fíjate que de la permutación 10 a la 25 apenas la p-valor se modifica, sin embargo, de la 1 a la 5 hay un cambio abismal. Cada nueva permutación añade una capa más de información y contexto sobre esta muestra inicialmente reducida.
Pros y contras de permutation test
Pros:
Permite no caer en falsos positivos o negativos con muestras muy, muy reducidas. ✅
Añade una capa extra de información ante este tipo de escenarios. ✅
Contras:
Es un poco más avanzado y ante stakeholders no técnicos puede ser complejo de abordar ❌
Funciona mejor conforme la muestra es más pequeña. Conforme aumenta la muestra, la p-valor final resultante es muy similar a lo que obtienes con un t-test💡
No aporta más potencia estadística al experimento, por lo tanto, no es como tal una solución perfecta para trabajar con bajas muestras ❌
4. CUPED
¿Recuerdas la siguiente figura? Te dije que la retuvieras. Ha llegado el momento de refrescar otra vez el cálculo del tamaño de la muestra. A continuación, vamos a desglosar esa fórmula a ver de qué se compone exactamente:
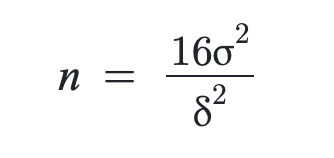
n: representa el tamaño de la muestra necesaria.
σ2: es la varianza de la población (o la estimación de esta).
δ: representa el MDE
Como ya señalé en el caso de las métricas, la variabilidad (es decir, la varianza) de los datos influye directamente en el diagnóstico pero, como podemos ver en esta fórmula simplificada, también en el cálculo de la muestra interviene la varianza.
Así, el tamaño de la muestra no se ve únicamente afectado por el efecto que queremos detectar, sino también por la varianza que tenemos entre manos, lo cual es un tema interesantísimo porque existen métricas con más varianza (ingresos, datos continuos) que otras (añadidos a carrito, datos discretos). A priori:
Cuanto mayor es la varianza de los grupos de un test AB, más muestra será necesaria independientemente del efecto.
Cuanto menor es la varianza de los grupos de un test AB, menor muestra será necesaria independientemente del efecto.
Así, la pregunta sobre la cual trabaja CUPED es la siguiente: ¿podemos reducir la varianza para así necesitar menos muestra? Fíjate que aquí no se trata tanto de trabajar con pequeñas muestras, sino de trabajar para reducir la muestra necesaria para realizar un diagnóstico adecuado.
Veamos esto con un ejemplo: tenemos un ecommerce de moda y deseamos evaluar si la variante de un test AB genera más ingresos que el grupo de control de manera estadísticamente significativa. Como tememos que habrá usuarios que realizarán transacciones muy elevadas y otras más reducidas, es posible que haya una varianza bastante elevada.
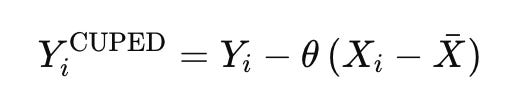
CUPED es una técnica diseñada para mejorar la potencia (es decir, la capacidad para determinar que existe un efecto cuando realmente existe) de un experimento reduciendo la varianza de los datos.
¿Cómo lo hacemos? mediante datos preexistentes como covariables para ajustar los resultados del test y eliminar parte de la varianza no explicativa (lo que podríamos considerar “ruido”). En vez de depender únicamente del resultado del test para explicar las diferencias entre control y variante, CUPED usa correlaciones basadas en datos históricos para «limpiar» ese ruido inherente. Esto significa que podemos identificar mejor los efectos de nuestra intervención con una muestra más pequeña.
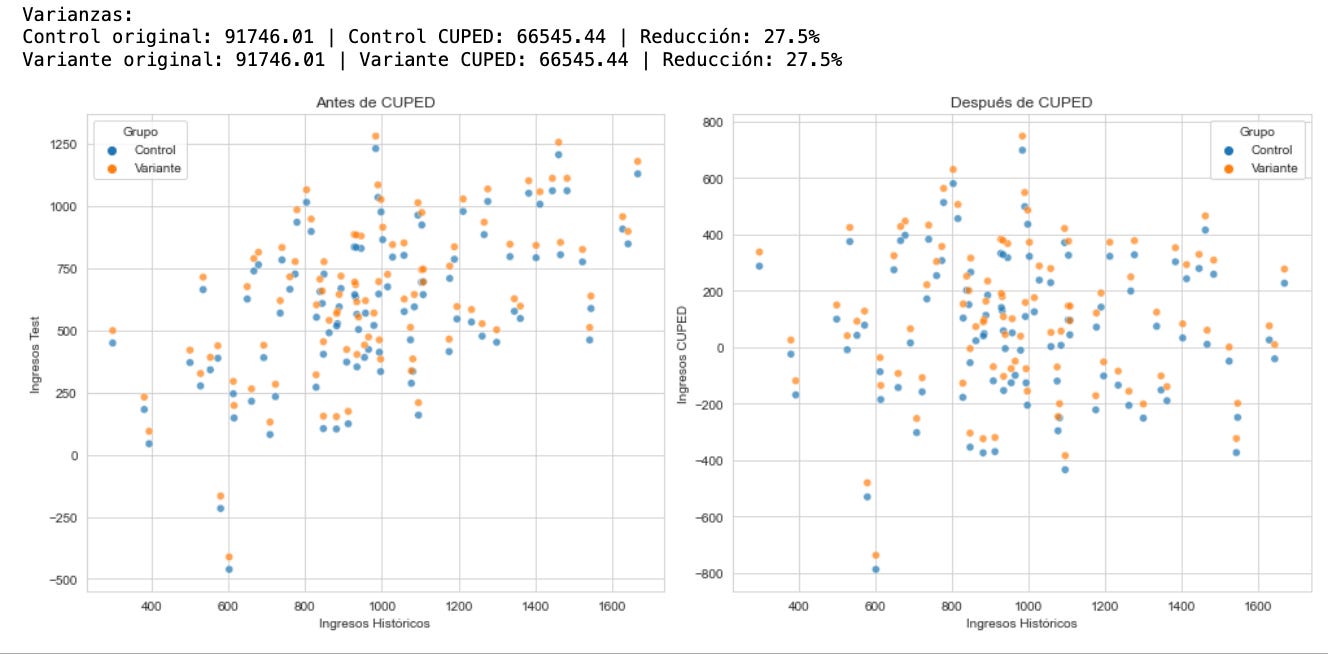
Al aplicar CUPED hemos logrado reducir la varianza en ambos grupos en un 27.5%. Esto significa que si antes necesitábamos 10 000 usuarios para detectar un efecto, ahora bastarían aproximadamente 7,250. Dicho de otro modo, un experimento que originalmente duraba 4 semanas se podría reducir a cerca de 2.9 semanas.
Pros y contras de CUPED
Pros:
Es un método contrastado que permite reducir la muestra de un experimento. ✅
No compromete a la potencia estadística del experimento al modificar la varianza ✅
Contras:
Funciona mejor con datos con alta varianza. Si no hay alta varianza, no funciona tan bien ❌
Si no tienes unas covariables, es decir, unas métrias que explican otras métricas para dibujar una correlación, no te funciona CUPED correctamente. La covariable y la métrica objetivo deben tener una correlación significativa (r > 0.3). Si no, no te servirá CUPED según Alex Deng. ❌
Es un tema súmamente técnico que requiere de una costumbre en la organización por el tratamiento de datos de forma avanzada 💡
Esto no acaba aquí
Como estás viendo no hay un método único, elegante y simple de trabajar con bajas muestras y, realmente, todo tiene unos pros y unas cotnras esenciales. No venía aquí a arrojaros soluciones simples a problemas complejos y casi irresolubles: la muestra suficiente es una cuestión obligatoria pero, como ves, hay atajos y aproximaciones interesantes.
Tanto es así que esto es solo una muestra de algunas aproximaciones. El resto lo compartí en un webinar gratuito que puedes ver en YouTube. Si además, te interesa la parte más técnica de CRO, tienes que saber que estamos trabajando en un programa avanzado de CRO.
CRO será técnico o no será.