#022 Causalidad en la práctica: DiD con Control Sintético (SCM)
¿Y si no puedes ejecutar un test AB? ¿Qué alternativas tenemos? continuamos con la serie de análisis causal con un caso práctico en el que aplico DiD en un problema de análisis en industria turística.

Primera edición de septiembre.
Esta vez continuamos con la serie que iniciamos en agosto sobre análisis causal. En la edición 020 introduje el concepto de análisis causal, un fenómeno dentro del campo del análisis de datos que introduce una serie de heurísticas que se pueden aplicar en bioestadística, medicina y, sí, también en el mundo del negocio digital. Te recomiendo empezar por esa edición de introducción si esto del análisis causal no te suena.
Si por el contrario ya estás algo familiarizado con este mundillo, en la presente edición mostraré un caso paso a paso para aplicar los principios del análisis causal a un problema de negocio offline de una industria fundamental en España: la turística.
Así empieza la 22ª edición de Leanalytics.
Causalidad en la práctica: DiD con Control Sintético (SCM)
Contexto
Imagina que trabajas como un científico de datos en una empresa hotelera ubicada en España. Un proveedor de la empresa sugiere a los directivos cambiar el contenido de la nevera de las habitaciones de los hoteles, ya que, según él, aumentará el margen. Él apunta a que, como contiene productos de mayor reconocimiento y calidad, los usuarios los identificarán al abrir la neverita y los consumirán, beneficiando a ambas partes.
Antes de confiar al 100% en la opinión del proveedor, se plantea ejecutar un experimento: probar en una serie de hoteles esta práctica a partir de un día determinado y ver la evolución de la métrica objetivo (margen) comparando el periodo previo y posterior al cambio.
Hasta aquí no hay nada que no sepas: muy a menudo en marketing digital tenemos retos de este tipo y en la edición 018 enseñé cómo medir el impacto de features en tu producto digital con ITSA, pero en este caso se trata de un cambio en un entorno offline (y sí, las reglas cambian).
Debemos tener en cuenta las siguientes consideraciones:
Por temas logísticos, solo podemos aplicar estos cambios en la Comunidad de Madrid, donde hay 12 de los 100 hoteles que tenemos en toda la península ibérica. No se pueden aplicar de manera aleatoria en unos hoteles de una comunidad u otra o en habitaciones concretas. En absoluto se puede ejecutar este cambio a huéspedes de forma aleatoria por mera logística y riesgo en la experiencia.
Un planteamiento razonable sería ejecutar un test AB dentro de los 12 hoteles de Madrid (6 con cambio vs. 6 sin cambio) para estimar si existe impacto. Sin embargo, para cuando te ha llegado la petición de análisis, desde dirección se ha decidido que el total de hoteles de Madrid tendrán este cambio y ya no hay marcha atrás.
Este último punto dificulta el análisis y es lo que provoca que debamos encontrar alternativas al Test AB. Pensando en alternativas a esta técnica es cuando nace el análisis causal y es lo que vamos a ver ahora: usaremos Diferencia en diferencias (DiD).
Análisis, unidad de tratamiento y medidas
¿En qué consiste DiD?
Diferencia en diferencias es un buen método para este tipo de situaciones. Consiste en comparar, entre un grupo tratado (los 12 hoteles de Madrid) y un grupo de control, el cambio de una métrica a partir de una intervención específica (modificar la nevera del hotel).
¿Y esto no es como un test AB? Se parece, pero no es igual. Un test AB aleatoriza unidades (veremos lo que es a continuación) y, por diseño, es el gold standard de la causalidad porque resuelve el problema fundamental de la inferencia causal: nunca vemos el contrafactual Y(0) del grupo tratado. Es decir, nunca veremos qué hubiera pasado si en Madrid no hubiéramos hecho cambios.
La aleatorización en el test AB garantiza exchangeability, es decir, que las unidades son intercambiables entre grupos, así que la diferencia entre control y variante es fruto del cambio. Esto no sucede en inferencia causal (en DiD) ya que aquí no hay aleatorización por mandato de dirección y dificultades logísticas.
Por eso usaremos DiD: construiremos el contrafactual de Madrid con la evolución del grupo control y del periodo pre, buscando tendencias paralelas. Así podremos evaluar si la sugerencia del proveedor genera impacto o no. Esto lo veremos al final de esta edición.
¿Y por qué no comparar una comunidad autónoma con otra y ya? Lo típico de comparar mercados de cuantía similar. Porque hay más variables que intervienen en el consumo de la nevera: la ocupación del hotel, los ingresos medios por habitación, entre otros.
Unidad de tratamiento
En la edición 020 se introduce brevemente algunos términos de análisis causal, pero hay bastante más lenguaje que vale la pena introducir en este caso. ¿Cuál sería el objeto de nuestro análisis? ¿el hotel? ¿la habitación? ¿el usuario? Es decir, ¿cuál es la unidad de nuestro estudio? Una unidad es el objeto del estudio que vamos a efectuar.
En nuestro caso, la unidad es el hotel. Necesitaremos un ID único de cada hotel y disponer de las métricas objetivo antes y después del tratamiento o intervención que vamos a ejecutar. En este caso, por temas logísticos suele ser complicado aleatorizar por habitaciones dentro de un hotel (por posibilidad de error, por ejemplo) y casi inviable aleatorizar el cambio por huésped. Experimentar en entornos offline es más complicado que en entornos online.
DAGs
¿La ocupación del hotel no puede ser un factor exógeno que afecta al margen que genera la nevera? Si has hecho esta pregunta: ¡Enhorabuena! Estás empezando a entender la naturaleza del análisis causal.
En la edición 020 te enseñé los DAGs. Estos nos sirven para construir una relación causal y entender visualmente las variables que influyen en el outcome. Antes de nada, utilizaremos dos métricas: el margen (€ por hotel y día) y el margen por habitación ocupada.
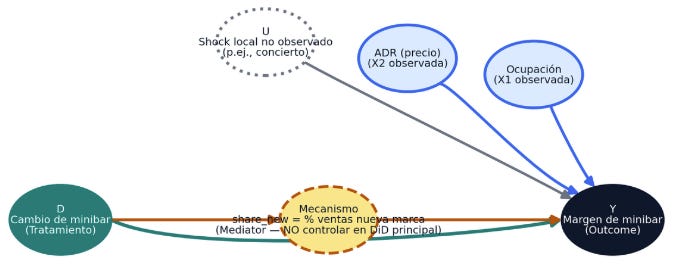
¿Qué tenemos en esta imagen?
U (unobserved): existen muchísimos elementos que no podemos (o es muy difícil) modelizar, como, por ejemplo, que Taylor Swift haga un concierto en Madrid después de que ejecutemos la intervención o aspectos como ferias, meteorología, entre otros. Estos elementos no están en nuestro dataset, pero podemos ponerlos encima de la mesa y hay multitud de artículos al respecto de cómo integrar lo desconocido en nuestros modelos (y se están haciendo hartos ejercicios práctico-teóricos al respecto). Si te interesa todo esto de lo “Unobserved”, puedes empezar por aquí con “Instrumental Variables Analysis”. En futuras ediciones sobre análisis causal ahondaremos en este fascinante tema.
D (Treatment): la modificación en el minibar.
X (Occupancy y ADR): asumimos que la ocupación de los hoteles es algo que afecta causalmente al outcome, así como la tarifa media diaria (ADR - Average daily rate), es decir, los ingresos de habitaciones / habitaciones ocupadas en un día y hotel. Cuánta más ocupación haya en un hotel (independientemente del tratamiento), más movimientos puede haber en la nevera.
Y (Outcome): El output, es decir, la métrica objetivo. El margen.
Mechanism (share_new): Se trata de un mediator entre treatment y outcome. Es el porcentaje de ventas del minibar que proviene de los SKUs del nuevo proveedor en un hotel y día. Se supone que el cambio en la nevera (D) aumenta share_new. Como esos SKUs tienen mayor margen por unidad, un share_new más alto eleva el margen total (Y).
Recuerda que las flechas establecen que una variable genera una relación causal hacia aquello a lo que apunta. En este caso Treatment afecta directamente al outcome pero también lo hace a través de un Mediator ubicado en medio. Un DAG, más allá de ser un dibujo con flechitas, nos permite entender de manera visual a qué nos estamos enfrentando.
El Reto: un tratamiento en Madrid
DiD y preparación de los datos
El tratamiento solamente sucede en Madrid. Esto introduce un potencial sesgo por todo lo anteriormente dicho. ¿Cómo podemos abordar esto? Básicamente, vamos a construir un control que tenga un comportamiento estadísticamente similar a Madrid previo al cambio (en cuanto a nivel y tendencia).
Para empezar, puedes descargar este CSV para que puedas ver algunas métricas que hemos considerado relevantes. Estas métricas a menudo vienen de la propia hipótesis y del conocimiento del sector. Añadir más variables no hará, necesariamente, que tus diagnósticos y modelos sean mejores.

Una vez tenemos los datos limpios y en el formato correcto, empezamos con el cacharreo serio.
Matching & Synthetic Control Method (SCM)
En lugar de elegir una o dos ciudades que “creemos” son similares a Madrid (lo típico que se hace en muchos departamentos de marketing), vamos a usar una técnica mejor: Synthetic Control Method (SCM).
¿Y si pudiéramos construir una versión sintética de Madrid a partir de una combinación ponderada de nuestros otros 88 hoteles? El método busca de forma algorítmica la "receta" perfecta, asignando un peso específico a varios hoteles de nuestro pool de control (los 88) para que, en conjunto, su comportamiento (su margen, su tendencia, su estacionalidad) antes de la intervención sea un clon lo más parecido posible del comportamiento de Madrid en ese mismo periodo. Este "gemelo estadístico" es nuestro Control Sintético, y será el contrafactual ideal contra el que compararemos el Madrid real tras el cambio.
Partimos de dos universos:
Los hoteles con tratamiento (Madrid)
Un pool elegible de hoteles fuera de Madrid.
Acotamos el análisis a la ventana de tiempo pre-intervención y, sobre esa ventana, resumimos la dinámica del outcome por hotel en un conjunto de métricas, en este caso:
Nivel medio del margen
Tendencia (pendiente temporal)
Patrón semanal que capture diferencias laborables–fin de semana.
ADR
Ocupación
El output que obtenemos es el siguiente:
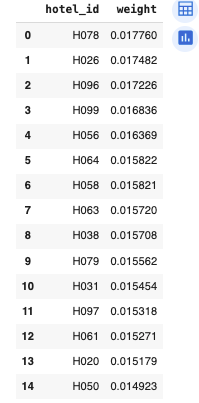
¿Qué significa esto? En esencia, cada fila es un hotel y su peso en el “Madrid sintético”. Pesos como los que se ven en la tabla, que son en torno al 1.5–1.8%, indican un grupo de control muy diversificado, lo que hace que, por ejemplo, no dependamos de un solo hotel como puede pasar. Si podemos contar con varios hoteles de manera diversa, nuestro grupo de control sintético será más fidedigno y similar al periodo pre-intervención de Madrid.
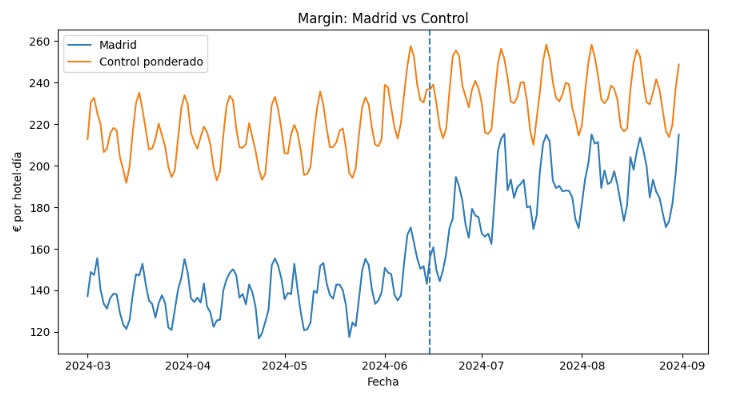
Así obtenemos un grupo de hoteles ponderado que es lo más parecido posible al grupo de Madrid pre-intervención. Con estos pesos cerrados, trazamos su trayectoria esperada sin intervención y comparamos Observado vs Control sintético en el periodo post-intervención para estimar el efecto causal vía DiD.
Pero… un momento: ¿Por qué necesitamos construir un contrafactual? ¿qué es exactamente un contrafactual? Como recordarás, el problema fundamental de la inferencia causal es que no podemos ver qué hubiera pasado si en Madrid no aplicamos el tratamiento: solamente podemos ver los datos de Madrid con tratamiento [Y(1)], más conocidos como factuales, pero jamás podremos ver qué hubiera pasado sin tratamiento [Y(0)], más conocido como contrafactual.
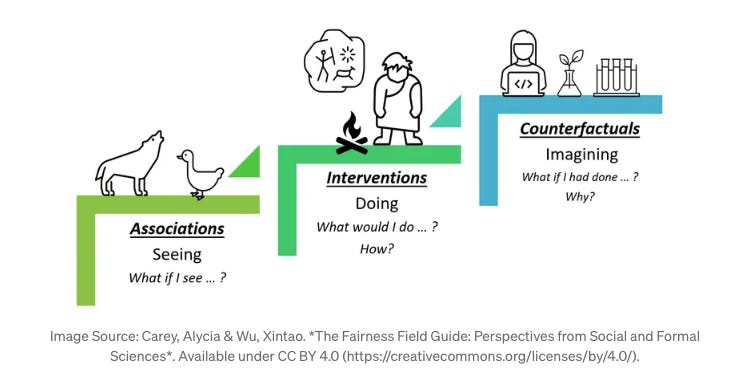
Y es que aquí viene lo mágico del análisis causal: nos permite matemáticamente imaginar mundos que jamás han existido. Sí, has leído bien: imaginar para establecer qué clase de relación existe entre los elementos. Es el máximo nivel dentro de la escalera de la causalidad de Judea Pearl que se mostró en la edición 020 y que te vuelvo a mostrar en la figura anterior.
Por que la pregunta no es qué impacto ha generado el cambio. Eso no lo podemos responder. La pregunta es “¿Qué hubiera pasado con el margen si no hubiéramos hecho ningún cambio?” La manera de formular la pregunta es lo que nos permite entender por qué necesitamos un contrafactual.
Pero, claramente, este contrafactual no lo inventamos de la nada. Al disponer de datos de otros 88 hoteles, podemos usar el SCM para construir una réplica de Madrid antes del cambio. Este grupo de control sintético" actuará como nuestro contrafactual observable y es precisamente lo que nos permitirá hacer el diagnóstico de tendencias paralelas que haremos a continuación.
Resultado del modelo y evaluación
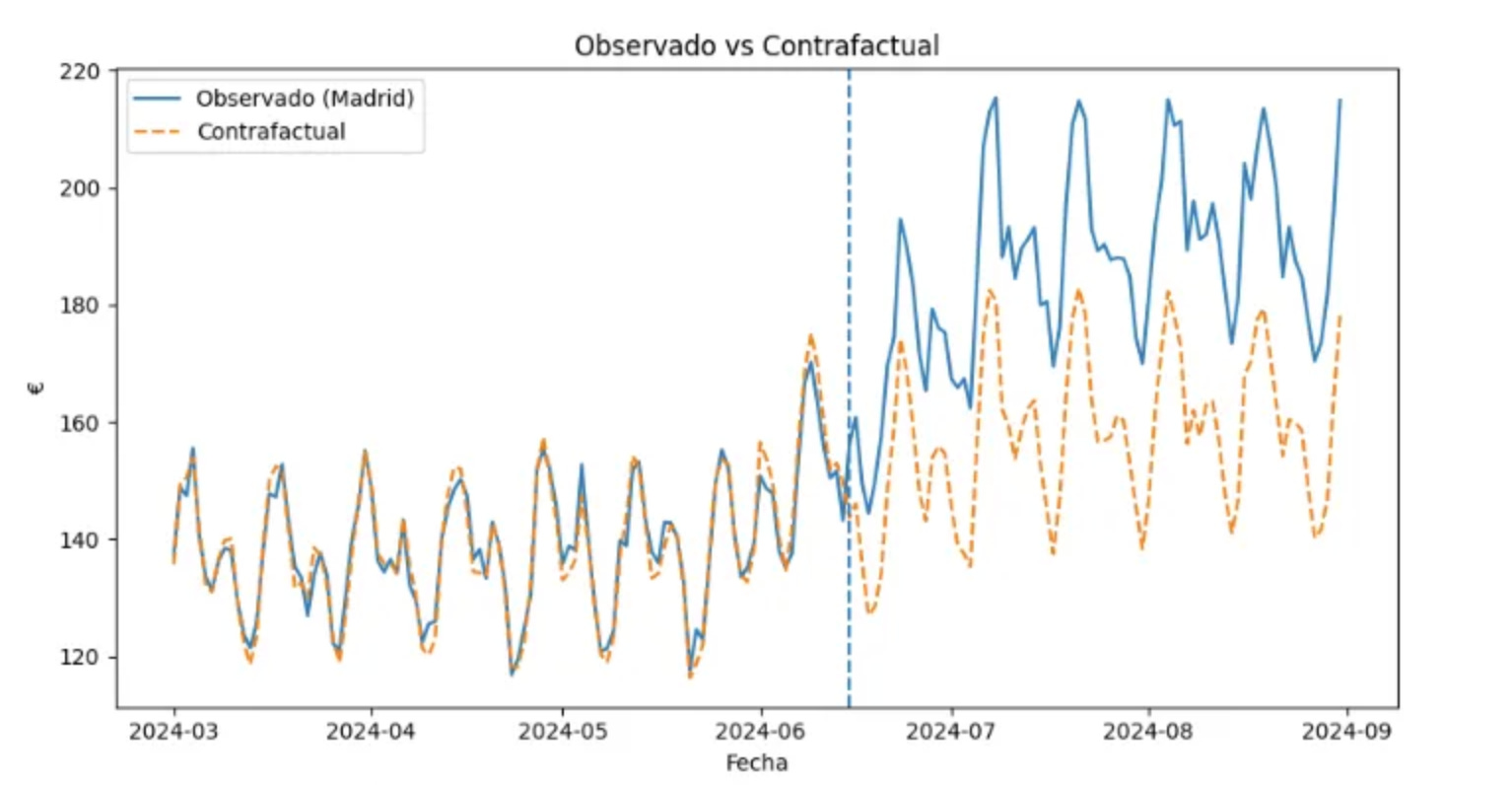
En la figura anterior vemos cómo el cambio en la nevera ha generado un impacto tremendo en los hoteles de Madrid. ¿Por qué podemos inferir que ha sido por el cambio en la nevera? Podría haber otros elementos estacionales. Podemos inferir esto gracias a que contamos con un grupo de control que no ha tenido ninguna afectación en la métrica objetivo si comparamos el periodo pre y post-intervención.
Ahora bien, una gráfica no prueba causalidad. Debemos evaluar el modelo y es aquí donde hay mucha tela que cortar. ¿Podemos fiarnos de estas gráficas? ¿podemos fiarnos de lo que ven nuestros ojos? Vamos a ver cómo evaluar si realmente nuestra intervención ha generado dicho impacto y en qué medida de manera causal.
Antes de nada, vamos a checkear con OLS (Ordinary Least Squares) ambos grupos para comprobar que, antes de la intervención, la diferencia Madrid−Control no tiene tendencia. Si el “gap” es plano en pre-intervención entre ambos grupos, la asunción de tendencias paralelas (necesaria para estimar el efecto) se cumple y ya podemos pasar a los siguientes pasos. Si el “gap” crece o cae de forma sistemática, hay que reconstruir el control y volver a empezar. Ejecutamos el siguiente código:
def slope(y):
t=np.arange(len(y)); return np.polyfit(t,y,1)[0] if len(y)>1 else 0.0
m_pre=mad_series[mad_series['date']<ref_date]
c_pre=ctrl_series[ctrl_series['date']<ref_date]
pre_df=m_pre.rename(columns={'margin':'m_mad'}).merge(c_pre.rename(columns={'margin':'m_ctrl'}), on='date')
pre_df=pre_df.sort_values('date').reset_index(drop=True)
pre_df['t']=np.arange(len(pre_df))
res_pre=smf.ols('(m_mad - m_ctrl) ~ t', data=pre_df).fit()
print(res_pre.summary())
print('Pendiente PRE Madrid:', slope(m_pre['margin'].values))
print('Pendiente PRE Control:', slope(c_pre['margin'].values))El output del código (que es solo de Madrid en periodo pre-intervención) nos muestra:
Intercept: nivel del margen del primer día preintervención que resulta que es alrededor de 134€/hotel-día.
t: la pendiente de Madrid en el periodo preintervención. Aumenta de manera estadísticamente significativa (p-valor = 0.005) en 0,0962€/día.
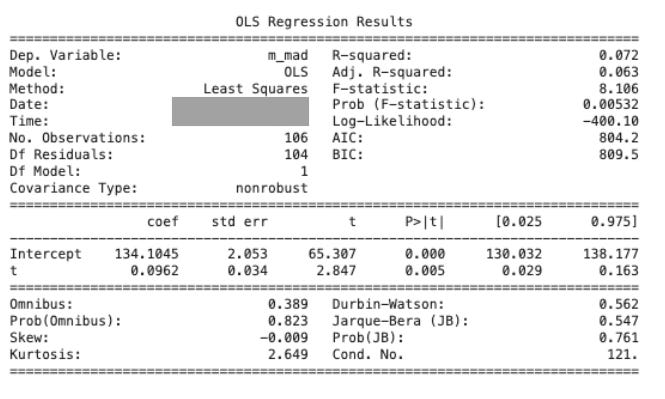
¿Por qué no sale “lo del control” ahí? Porque esa tabla no compara grupos; es una regresión univariada. A continuación, realizamos el siguiente que busca directamente asumir si la tendencia pre-intervención entre el grupo de control y los hoteles de Madrid son paralelas:
m_pre = mad_series[mad_series['date'] < ref_date].rename(columns={'margin':'m_mad'})
c_pre = ctrl_series[ctrl_series['date'] < ref_date].rename(columns={'margin':'m_ctrl'})
pre_df = (m_pre.merge(c_pre, on='date')
.sort_values('date')
.assign(gap=lambda x: x['m_mad'] - x['m_ctrl'],
t=lambda x: np.arange(len(x))))
X = sm.add_constant(pre_df['t'])
mod = sm.OLS(pre_df['gap'], X).fit(cov_type='HAC', cov_kwds={'maxlags':7})
print(mod.summary().tables[1])
print(f"Pendiente gap PRE: {mod.params['t']:.4f} | p-valor: {mod.pvalues['t']:.3f}")
# Visual rápido: gap PRE
plt.figure()
plt.plot(pre_df['date'], pre_df['gap'])
plt.axhline(0, ls=':')
plt.title('Gap PRE (Madrid - Control)')
plt.xlabel('Fecha'); plt.ylabel('€'); plt.tight_layout(); plt.show()
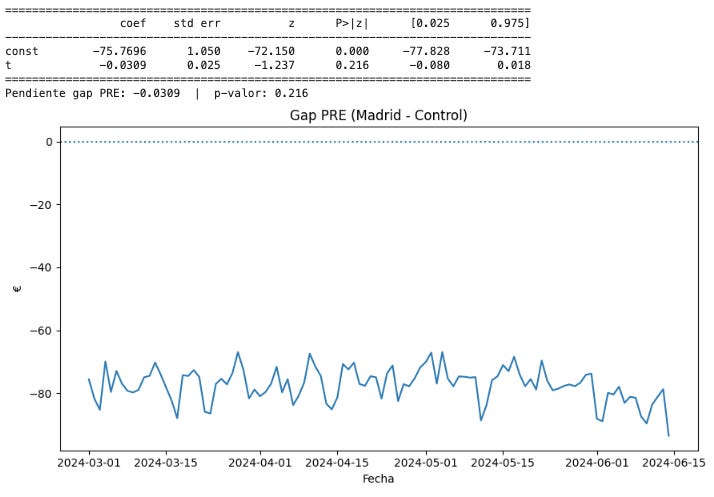
Aquí vemos el output del anterior código. Debido a que la p-valor no es estadísticamente significativa (es superior a 0.05), podemos validar la asunción de tendencias paralelas o, como mínimo, es plausible asumir esto. Igualmente, que la pendiente sea -0,0309 significa que antes del cambio el gap entre control y los hoteles de Madrid se estrechaba muy levemente. Sin embargo, como no es estadísticamente significativo, no podemos decir que sea distinto de 0 (que es lo que buscamos).
TWFE (Two-way Fixed Effects)
Con TWFE buscamos estimar el efecto causal de un tratamiento que cambia con el tiempo como tenemos en este caso. ¿Cómo lo hacemos? aplicando una regresión con efectos fijos por hotel y por fecha.
Veámoslo con un ejemplo: si el Hotel A tiene un margen “propio” de 100€ y ese día, en promedio, todos los hoteles están 10 puntos por encima, una observación de 120 se convierte en un “residuo” ≈ 120 − 100 − 10 = 10. La regresión usa esos residuos de margen y de las variables explicativas para ver si los hoteles con tratamiento (los de Madrid), tras el cambio, suben más que lo esperable por su hotel y por el día. Así quitamos (es decir, absorbemos) “ser un hotel A” y “ser un domingo” del análisis.
Esto permite aislar el efecto del cambio de la nevera del resto del ruido. Al quitar lo fijo de cada hotel y lo común de cada día, el modelo compara la variación dentro del hotel y dentro del día.

D es el cambio de Madrid frente a su contrafactual (29,08€/hotel-día). Si asumimos tendencias paralelas (que hemos hecho con el anterior cálculo), lo podemos interpretar como el efecto causal medio (ATT = Average Treatment Effect on the Treated). Es importante destacar el intervalo de confianza entre 21,34 y 36,81.
¿Y occ (ocupación) y adr (average daily rate)? Los tratamos como covariables. Es decir, como dijimos en la anterior edición, como variables que pueden influir tanto en la métrica objetivo como en el tratamiento. Es importante entender que no son como tal causas del margen, ya que su coeficiente resulta una correlación condicional y no causal.
¿Para qué nos sirven? para reducir ruido y ganar precisión en la estimación de D. Al “absorber” la parte de margin explicada por la ocupación (occ) y el precio (adr), el error residual baja y el estimador del efecto del cambio de minibar sale más estable y con menor error estándar. Eso sí, solo los usamos como controles de precisión si no son “bad controls” (es decir, si el tratamiento no los altera). Para comprobar esto, sencillamente debemos ejecutar el siguiente código:
specs = {
"base": "margin ~ D + C(hotel_id) + C(date)",
"+occ": "margin ~ D + occ + C(hotel_id) + C(date)",
"+occ+adr": "margin ~ D + occ + adr + C(hotel_id) + C(date)",
}
for name, f in specs.items():
res = smf.ols(f, data=work).fit(cov_type='cluster',
cov_kwds={'groups': work['hotel_id']})
print(f"{name:8s} D = {res.params['D']:.2f} (se={res.bse['D']:.2f}, p={res.pvalues['D']:.3g})")
# 2) Falsificación: ¿el tratamiento mueve occ o adr? (no debería)
for y in ['occ','adr']:
res = smf.ols(f"{y} ~ D + C(hotel_id) + C(date)", data=work)\
.fit(cov_type='cluster', cov_kwds={'groups': work['hotel_id']})
print(f"{y}: efecto de D = {res.params.get('D', float('nan')):.3f} p={res.pvalues.get('D', float('nan')):.3g}")Como es similar al valor de D anteriormente mostrado (29,08€/hotel-día) y, sobre todo, porque no es estadísticamente significativo, podemos asumir que D no afecta a occ ni adr, así que incluirlos no sesga el tratamiento y pueden ser covariables como han sido hasta ahora.

Event Study
Un event-study es la radiografía dinámica del efecto. En vez de dar un único número promedio, estimamos un coeficiente para cada día relativo al cambio (k): días “lead” antes del 0 (que sería el periodo pre-intervención) y “lag” después (periodo post-intervención). Así comprobamos dos cosas a la vez:
Que la tendencia PRE sea plana (la asunción de tendencias paralelas)
Cómo evoluciona el impacto tras la intervención.
¿Por qué volver a calcular la asunción de tendencias paralelas? Porque el test previo miraba algo muy concreto (el gap medio), pero el event-study es más fino: pone un indicador por día y comprueba si hubo anticipación (efectos antes del día pre-intervención), curvaturas o baches PRE que un slope promedio puede no detectar.
¿Y qué ganamos si ya teníamos el valor de 29,08€/hotel-día? El DiD da una cifra media, pero el event-study te da la película entera: cuándo aparece el efecto, si despega poco a poco, si se agota o se acelera, y cuánto ruido/incertidumbre hay en cada tramo (bandas IC). El event-study no reemplaza al DiD: lo audita y lo enriquece mostrando la dinámica causal completa.
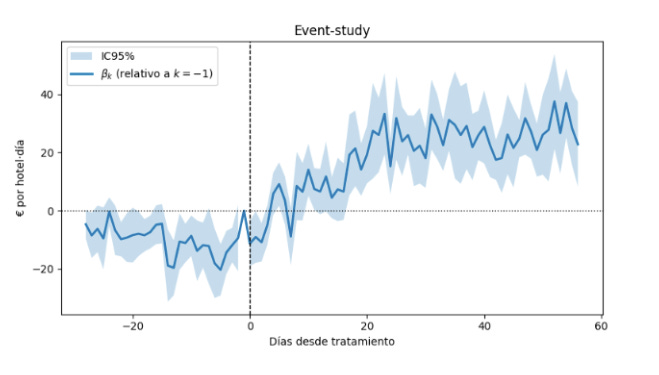
¿Cómo se interpreta esto? Antes del día del cambio en Madrid, las bandas del intervalo de confianza están cerca de 0, lo cual es buena señal: serían parámetros paralelos. Tras el día del cambio vemos un salto positivo: a partir de k = 10 los βk rondan +20 € a +40 € por hotel·día y el 0 queda fuera del IC en buena parte de las fechas. Eso sugiere un efecto causal creciente (rampa) más que un pico efímero.
Donut, Placebo Test & Leave-one-city-out
Para finalizar, vamos a estresar el modelo con tres técnicas de evaluación adicionales:
Donut: Excluye días cercanos al día de inicio del tratamiento para evitar contaminación y estima el efecto.
Placebo Test: Mueve artificialmente la fecha del tratamiento al pasado y verifica que el efecto estimado sea nulo. Muy útil en contextos de este tipo.
Leave-one-city-out (LOCO): Reestima el modelo excluyendo una ciudad y comprueba que el resultado no dependa de ese mercado. También muy adecuado en este contexto.
El output que obtenemos es el siguiente:

Donut: pese a perder días en el análisis, el efecto es prácticamente igual.
Placebo test: el placebo da −4.02 y p-valor igual a 0.005. Es decir, es pequeño pero significativo y señala algo de estacionalidad en el periodo pre-intervención no capturada. No invalida el resultado, pero pide cautela porque podría indicar que el efecto depende de una rampa ascendente previa. En este caso se debería averiguar si hay algo de ruido en los datos repitiendo los placebos en distintas ventanas de tiempo o incluso ejecutar permutaciones.
Leave-one-city-out (LOCO): Al quitar Zaragoza se obtiene 26.53, casi idéntico al principal. El hallazgo no depende de esa plaza y tenemos un modelo interesante. Una buena práctica es repetir LOCO con otras ciudades.
Falsificaciones
Una buena manera de acabar de evaluar un modelo de DiD es mediante una falsificación, la cual sirve para comprobar que nuestro método no detecta “efectos” cuando no debería. Es decir: si no hubiera intervención, es decir, si no hubiéramos hecho ningún cambio en los 12 hoteles de Madrid, ¿mi DiD produciría 0? La idea es que sí. Estas pruebas atacan sesgos por pre-tendencias, estacionalidad mal capturada, entre otros.
¿Cómo lo hacemos? Utilizamos occ y adr como respuesta del modelo en dos regresiones separadas en las que usamos D (el tratamiento) para así cuadrar que la intervención no mueve ocupación o precio una vez controlas por hotel y fecha. Así medimos el cambio medio en ocupación (occ) o precio (adr) cuando D=1 (tratado) frente a D=0, manteniendo constante cada hotel y cada fecha. El resultado es muy adecuado como podemos ver en la siguiente figura:

Gráfica final con contrafactual
Es aquí cuando vamos a construir el contrafactual. Justamente cuando hacemos work.copy y definimos “D = 0”. Lo pongo en negrita para que se vea más fácil. Anteriormente, nuestras estimaciones del modelo han sido con el grupo de control que hemos generado a partir de los 88 hoteles restantes y que no están presentes en Madrid.
treated_post=work['treated'].eq(1) & work['D'].eq(1)
pred=twfe.predict(work)
cf=work.copy(); cf.loc[treated_post, 'D']=0
pred_cf=twfe.predict(cf)
agg=(work[work['treated']==1].assign(yh=pred, yh_cf=pred_cf)
.groupby('date', as_index=False).agg(actual=('margin','mean'), cf=('yh_cf','mean')))
agg['att_t']=agg['actual']-agg['cf']
plt.figure(); plt.plot(agg['date'], agg['actual'], label='Observado (Madrid)');
plt.plot(agg['date'], agg['cf'], linestyle='--', label='Contrafactual');
plt.axvline(ref_date, linestyle='--'); plt.title('Observado vs Contrafactual');
plt.xlabel('Fecha'); plt.ylabel('€'); plt.legend(); plt.tight_layout(); plt.show()
print('ATT medio post (€/hotel·día):', agg.loc[agg['date']>=ref_date,'att_t'].mean())Ahora hemos justo creado el contrafactual, es decir, el mundo que imaginamos y que responde a la pregunta “¿Qué hubiera pasado con el margen si no hubiéramos hecho ningún cambio?” En la siguiente figura puedes ver cómo hubiera evolucionado la métrica objetivo si nunca hubiéramos hecho caso al proveedor. Como se puede ver, el ATT es de 29,08€/hotel-día. Este contrafactual es la predicción que hace el modelo para Madrid fijando D = 0 en TWFE, mientras que el gemelo sintético son los datos observados de otros hoteles combinados con pesos para emular a Madrid en pre-intervención.
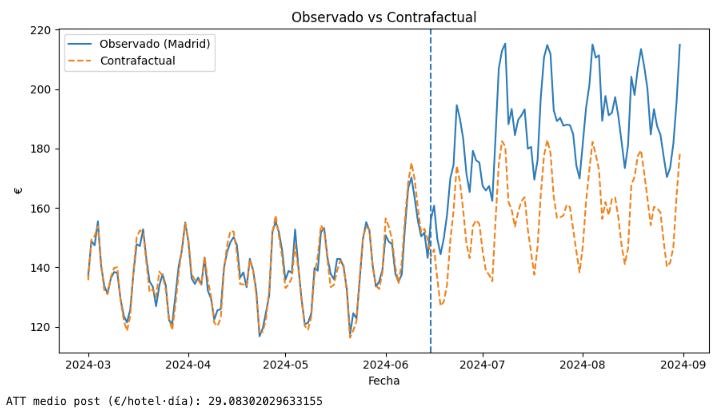
Cambiar el contenido de la nevera en Madrid elevó el margen en alrededor de 29€/hotel-día. Las pre-tendencias son paralelas, el efecto aparece tras el cambio y se mantiene.
Ideas clave
Aquí algunas de las ideas clave:
DiD permite hacernos preguntas que están en pleno mundo de la imaginación: “¿Qué hubiera pasado con el margen si no hubiéramos hecho ningún cambio?”
Las alternativas serias al test AB son fascinantes y forman parte de la familia del análisis causal. Son alternativas sinceramente más técnicas, pero que una vez dominadas son altamente efectivas.
Los métodos de evaluación son fundamentales y es donde más horas dedicarás. Son los que determinan si tu modelo tiene la suficiente calidad como para apuntar que existe una relación causal entre un fenómeno y otro.
Dominar estas técnicas nos permite dejar de ser meros observadores de datos para convertirnos en arquitectos de decisiones estratégicas, estimando el verdadero impacto de cada acción que tomamos.
Libros recomendables:
The Book Of Why - Judea Pearl
Causal Inference in Python - Mateus Facure
Causal Inference for Data Science - Aleix Ruiz de Villa
Inferencia y descubrimiento causal en Python - Aleksander Molak
Causal AI - Robert Osazuwa